Maybe don't give language models standardized tests
Feb 27, 2024
 Figure 1: Dragons in the evals waters
Figure 1: Dragons in the evals waters
After training a language model, it would be nice to say something about how good it is. The standard machine learning performance metric is loss, but this value is neither human-interpretable nor comparable across models. The solution offered by natural language processing researchers to this problem is to build benchmark datasets. Even if the benchmark is carefully constructed, a model's performance on the benchmark dataset will be difficult to compare to human performance. For example, if your benchmark tests knowledge in 57 subject areas, do we really expect any individual human to do well on this task?
I imagine this dilemma is the motivation for evaluating language models on standardized tests. These tests are designed to measure the intelligence of humans, taken by a large number of people, and scored in a consistent way. If it were possible to administer the same test to a language model, model intelligence could be directly compared against a population of humans. Some LLM labs have published model evaluations of this kind and compared performance to humans, e.g. OpenAI and Anthropic.
As a general rule: every time you think you've found a new good evaluation method, you haven't. There's always some detail you haven't considered.2
I personally want to discuss why it's nearly impossible to fairly compare LLM performance on standardized tests to human performance. To be clear, this is not yet a particularly popular evaluation method, but I find it a particularly misleading one. Think of this post as a metaphorical "here be dragons" sign.
By way of example, let's discuss how one would evaluate GPT-4 on the Math portion of a recent SAT test.
The SAT Test
Most questions on the SAT are straightforward to transcribe into a format that LMs can understand:
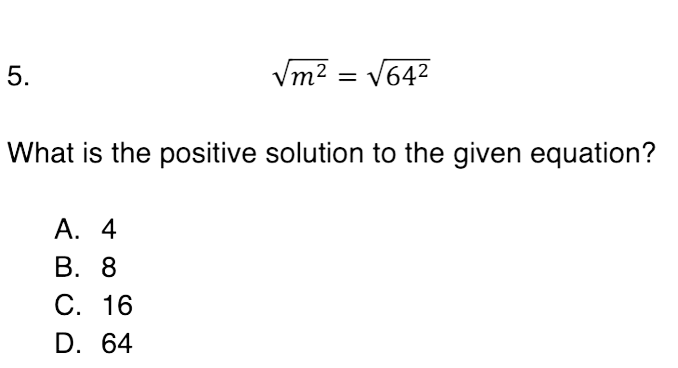
$\sqrt(m^2) = $\sqrt(64^2)
What is the positive solution to the given equation?
A. 4
B. 8
C. 16
D. 64
But some questions are not so straightforward:
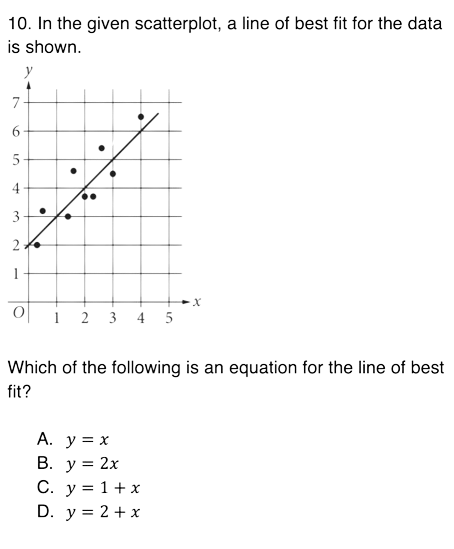 About 30% of Math questions on the October 2023 SAT have a plot or graphic of some kind.
About 30% of Math questions on the October 2023 SAT have a plot or graphic of some kind.
Evaluating vision-enabled models
If you have a vision-enabled model, the solution is simple. you pass either the whole question as an image or just the images plus question text to your model. In the GPT-4 technical report, OpenAI describe using this methodology to evaluate their vision models.
I chose to give images of the whole question to the vision model, as sometimes the answer choices themselves were images. Using this method, GPT-4 has an accuracy of 0.690.
I have relatively few qualms with this particular evaluation method because "waking up and answering a series of seemingly random math questions" somewhat accurately describes the experience of taking the SAT as a high-schooler. As more and more models are published multi-modal by default, perhaps this will be the way to fairly administer standardized tests.
One small inconsistency between this method and the way that students are evaluated is that the SAT does not measure a student's eyesight. The College Board does not penalise a student for having poor eyesight and offers a large-print accommodation is offered, but we know that GPT-4 struggles with reading small text and accurate spatial localisation. What would be the equivalent large-print accommodation for GPT-4?
Representing images to vision models is simple; how should we represent graphs and image to language-only models such that the final results are comparable?
Evaluating language-only models
1. Ignore the image.
Obviously bad. The questions with plots are meaningless without them - that's up to 30% of problems. This would make your results inherently incomparable.
In the appendix of the GPT-4 technical report, OpenAI write about doing essentially this:
When evaluating text models on multiple-choice questions, we included a text tag stating IMAGE: with a non-meaningful filename wherever an image would be missing. This allows us to lower-bound the text-based models’ performance on multiple-choice exams.
Using this method, GPT-4 has an accuracy of 0.672 on my run.
My estimate for the accuracy using this method would be, in essence, ~0.9 (given the experiment below) for the non-image questions plus 4 questions (1 out of 4 chances of picking the answer randomly times 16 image questions), which is something like (0.9*(58-16)+4)/58 which is about 0.72. Similar enough.
2. Remove all questions containing images.
This is slightly better since you're not giving meaningless questions to the model, but you can't compare the model's performance on a subset.
Using this method, GPT-4 has an accuracy of 0.881.
3. Attach ASCII art.
 Lol I guess you could do this. Technically the model could do this task by counting newline characters and locating the line, but no training data really prepares a model for such a task, and is this really the capability you aim to evaluate?
Lol I guess you could do this. Technically the model could do this task by counting newline characters and locating the line, but no training data really prepares a model for such a task, and is this really the capability you aim to evaluate?
I didn't run this; too much work for this level of silliness.
4. Attach code for the plot.
We could provide code for the image as generated by some sort of plotting/graphics library. This is the least-worst method for a language-only model I know about, since the model was trained to understand code.
The MATH dataset formats all diagrams as Asymptote Vector Graphics Language (asy) code. This a relatively simple tool that's used with LaTex, and since the equations in the question are typically formatted as LaTex, this is all consistent. Nevertheless, choosing to represent graphics in asy means that you will not just be testing your model's performance on your standardized test but also implicitly testing it's ability to understand asy. This will introduce some inconsistency between the human test and model test, and this is unfortunately true of whatever language you choose to represent your graphics in. A serious researcher would definitely set a baseline on the ability of the model to understand the graphics language.4 The Hendrycks MATH dataset is pretty popular, and GPT-4 was finetuned on a portion of the MATH questions, so asy seems like a not-terrible choice.
In order to convert each individual graphic to asy for the model, you'll have to
choose how to represent the question to the model because there's not one way to write code for a given graphic. The representation, of course, will impact how the model solves the problem.
In the question I showed before, you need to represent the datapoints and the "line of best fit." Representing the data points is somewhat unambiguous given that it's a scatterplot in 2D space, but there are (at least) two ways to represent the line. You could write a function that plots the correct line
real slope = 1;
real intercept = 2;
real f(real x) { return slope*x + intercept; };
draw(graph(f, 0,5), graphPen);
or you could draw a line between two points on the line and not reveal the equation of the line.
draw((0, 2)--(4,6));
The original question was about determining the equation of the line of best fit, so the first method would be revealing way more information to the model than the second.
As you convert the graphics to code, you could be revealing the answer to your model with these questions. The simulated test now seems less and less valid. Even if you're very careful and reveal as little information as possible, a model seeing code for a graph is not comparable to a human looking at an image.
Using this method, GPT-4 has an accuracy of 0.845.
Dragons
Given that the waters are riddled with problems and dragons, maybe the solution is to evaluate language-only models on text-only datasets. The versions of these tests that are simulated for language-only models are too dissimilar to be directly comparable to human performance.
Should you really want to evaluate a model on the non-image portions of a standardized test, state clearly that the comparison isn't entirely fair. This is the approach taken by the MedPaLM authors - emphasis mine:
Large language models (LLMs) have catalyzed significant progress in medical question answering; Med-PaLM was the first model to exceed a “passing” score in US Medical Licensing Examination (USMLE) style questions with a score of 67.2% on the MedQA dataset.
In summary, beware the dragons in the evals waters. Choose datasets where comparison is actually possible, and don't be misleading.
All evals were performed using the "natural use case" method of evaluation. Give the model the question and allow it to sample as many tokens as you would like, and use another model (here, GPT-3) to compare the reference with the sampled answer and judge correctness.
Dataset and scripts can be found on github.
-
Anthropic's policy team have written an excellent blog post about this ↩
-
I like to think of myself as a serious researcher, but my time is limited, so I did a fake lil eval and evaluated GPT-4's ability to comprehend
asyby picking 15 examples from the Asymptote gallery and asked the model to tell me what's in the picture. It had one major hallucination and 7 minor hallucinations. The hallucinations were all about the details of howasyis rendered, e.g. thatasydoes color addition as light and not as pigment. Besides the one major hallucination, GPT-4 can describe the "general" shape of every image that I picked, including the ones that are just "shapes". A .txt file with quick results is included on github. I thought about, you know, making a real benchmark, but this just not a good use of one's time in the age of GPT-4-V and Gemini 1.5. ↩